Interoperability¶
Bohrium is interoperable with other popular Python projects such as Cython and PyOpenCL. The idea is that if you encounter a problem that you cannot implement using array programming and Bohrium cannot accelerate, you can manually accelerate that problem using Cython or PyOpenCL.
NumPy¶
One example of such a problem is bincount() from NumPy. bincount() computes a histogram of an array, which isn’t possible to implement efficiently through array programming. One approach is simply to use the implementation of NumPy:
import numpy
import bohrium
def bincount_numpy(ary):
# Make a NumPy copy of the Bohrium array
np_ary = ary.copy2numpy()
# Let NumPy handle the calculation
result = numpy.bincount(np_ary)
# Copy the result back into a new Bohrium array
return bohrium.array(result)
In this case, we use bohrium._bh.ndarray.copy2numpy() and bohrium.array() to copy the Bohrium to NumPy and back again.
Cython¶
In order to parallelize bincount() for a multi-core CPU, one can use Cython:
import numpy as np
import bohrium
import cython
from cython.parallel import prange, parallel
from libc.stdlib cimport abort, malloc, free
cimport numpy as cnp
cimport openmp
ctypedef cnp.uint64_t uint64
@cython.boundscheck(False) # turn off bounds-checking
@cython.cdivision(True) # turn off division-by-zero checking
cdef _count(uint64[:] x, uint64[:] out):
cdef int num_threads, thds_id
cdef uint64 i, start, end
cdef uint64* local_histo
with nogil, parallel():
num_threads = openmp.omp_get_num_threads()
thds_id = openmp.omp_get_thread_num()
start = (x.shape[0] / num_threads) * thds_id
if thds_id == num_threads-1:
end = x.shape[0]
else:
end = start + (x.shape[0] / num_threads)
if not(thds_id < num_threads-1 and x.shape[0] < num_threads):
local_histo = <uint64 *> malloc(sizeof(uint64) * out.shape[0])
if local_histo == NULL:
abort()
for i in range(out.shape[0]):
local_histo[i] = 0
for i in range(start, end):
local_histo[x[i]] += 1
with gil:
for i in range(out.shape[0]):
out[i] += local_histo[i]
free(local_histo)
def bincount_cython(x, minlength=None):
# The output `ret` has the size of the max element plus one
ret = bohrium.zeros(x.max()+1, dtype=x.dtype)
# To reduce overhead, we use `interop_numpy.get_array()` instead of `copy2numpy()`
# This approach means that `x_buf` and `ret_buf` points to the same memory as `x` and `ret`.
# Therefore, only change or deallocate `x` and `ret` when you are finished using `x_buf` and `ret_buf`.
x_buf = bohrium.interop_numpy.get_array(x)
ret_buf = bohrium.interop_numpy.get_array(ret))
# Now, we can run the Cython function
_count(x_buf, ret_buf))
# Since `ret_buf` points to the memory of `ret`, we can simply return `ret`.
return ret
The function _count() is a regular Cython function that performs the histogram calculation. The function bincount_cython() uses bohrium.interop_numpy.get_array() to retrieve data pointers from the Bohrium arrays without any data copying.
Note
Changing or deallocating the Bohrium array given to bohrium.interop_numpy.get_array() invalidates the returned NumPy array!
PyOpenCL¶
In order to parallelize bincount() for a GPGPU, one can use PyOpenCL:
import bohrium
import pyopencl as cl
def bincount_pyopencl(x):
# Check that PyOpenCL is installed and that the Bohrium runtime uses the OpenCL backend
if not interop_pyopencl.available():
raise NotImplementedError("OpenCL not available")
# Get the OpenCL context from Bohrium
ctx = bohrium.interop_pyopencl.get_context()
queue = cl.CommandQueue(ctx)
x_max = int(x.max())
# Check that the size of histogram doesn't exceeds the memory capacity of the GPU
if x_max >= interop_pyopencl.max_local_memory(queue.device) // x.itemsize:
raise NotImplementedError("OpenCL: max element is too large for the GPU")
# Let's create the output array and retrieve the in-/output OpenCL buffers
# NB: we always return uint32 array
ret = bohrium.empty((x_max+1, ), dtype=np.uint32)
x_buf = bohrium.interop_pyopencl.get_buffer(x)
ret_buf = bohrium.interop_pyopencl.get_buffer(ret)
# The OpenCL kernel is based on the book "OpenCL Programming Guide" by Aaftab Munshi at al.
source = """
kernel void histogram_partial(
global DTYPE *input,
global uint *partial_histo,
uint input_size
){
int local_size = (int)get_local_size(0);
int group_indx = get_group_id(0) * HISTO_SIZE;
int gid = get_global_id(0);
int tid = get_local_id(0);
local uint tmp_histogram[HISTO_SIZE];
int j = HISTO_SIZE;
int indx = 0;
// clear the local buffer that will generate the partial histogram
do {
if (tid < j)
tmp_histogram[indx+tid] = 0;
j -= local_size;
indx += local_size;
} while (j > 0);
barrier(CLK_LOCAL_MEM_FENCE);
if (gid < input_size) {
atomic_inc(&tmp_histogram[input[gid]]);
}
barrier(CLK_LOCAL_MEM_FENCE);
// copy the partial histogram to appropriate location in
// histogram given by group_indx
if (local_size >= HISTO_SIZE){
if (tid < HISTO_SIZE)
partial_histo[group_indx + tid] = tmp_histogram[tid];
}else{
j = HISTO_SIZE;
indx = 0;
do {
if (tid < j)
partial_histo[group_indx + indx + tid] = tmp_histogram[indx + tid];
j -= local_size;
indx += local_size;
} while (j > 0);
}
}
kernel void histogram_sum_partial_results(
global uint *partial_histogram,
int num_groups,
global uint *histogram
){
int gid = (int)get_global_id(0);
int group_indx;
int n = num_groups;
local uint tmp_histogram[HISTO_SIZE];
tmp_histogram[gid] = partial_histogram[gid];
group_indx = HISTO_SIZE;
while (--n > 0) {
tmp_histogram[gid] += partial_histogram[group_indx + gid];
group_indx += HISTO_SIZE;
}
histogram[gid] = tmp_histogram[gid];
}
"""
source = source.replace("HISTO_SIZE", "%d" % ret.shape[0])
source = source.replace("DTYPE", interop_pyopencl.type_np2opencl_str(x.dtype))
prg = cl.Program(ctx, source).build()
# Calculate sizes for the kernel execution
local_size = interop_pyopencl.kernel_info(prg.histogram_partial, queue)[0] # Max work-group size
num_groups = int(math.ceil(x.shape[0] / float(local_size)))
global_size = local_size * num_groups
# First we compute the partial histograms
partial_res_g = cl.Buffer(ctx, cl.mem_flags.WRITE_ONLY, num_groups * ret.nbytes)
prg.histogram_partial(queue, (global_size,), (local_size,), x_buf, partial_res_g, np.uint32(x.shape[0]))
# Then we sum the partial histograms into the final histogram
prg.histogram_sum_partial_results(queue, ret.shape, None, partial_res_g, np.uint32(num_groups), ret_buf)
return ret
The implementation is regular PyOpenCL and the OpenCL kernel is based on the book “OpenCL Programming Guide” by Aaftab Munshi et al.
However, notice that we use bohrium.interop_pyopencl.get_context() to get the PyOpenCL context rather than pyopencl.create_some_context().
In order to avoid copying data between host and device memory, we use bohrium.interop_pyopencl.get_buffer() to create a OpenCL buffer that points to the device memory of the Bohrium arrays.
PyCUDA¶
The PyCUDA implementation is very similar to the PyOpenCL. Besides some minor difference in the kernel source code, we use bohrium.interop_pycuda.init() to initiate PyCUDA and use bohrium.interop_pycuda.get_gpuarray() to get the CUDA buffers from the Bohrium arrays:
def bincount_pycuda(x, minlength=None):
"""PyCUDA implementation of `bincount()`"""
if not interop_pycuda.available():
raise NotImplementedError("CUDA not available")
import pycuda
from pycuda.compiler import SourceModule
interop_pycuda.init()
x_max = int(x.max())
if x_max < 0:
raise RuntimeError("bincount(): first argument must be a 1 dimensional, non-negative int array")
if x_max > np.iinfo(np.uint32).max:
raise NotImplementedError("CUDA: the elements in the first argument must fit in a 32bit integer")
if minlength is not None:
x_max = max(x_max, minlength)
# TODO: handle large max element by running multiple bincount() on a range
if x_max >= interop_pycuda.max_local_memory() // x.itemsize:
raise NotImplementedError("CUDA: max element is too large for the GPU")
# Let's create the output array and retrieve the in-/output CUDA buffers
# NB: we always return uint32 array
ret = array_create.ones((x_max+1, ), dtype=np.uint32)
x_buf = interop_pycuda.get_gpuarray(x)
ret_buf = interop_pycuda.get_gpuarray(ret)
# CUDA kernel is based on the book "OpenCL Programming Guide" by Aaftab Munshi et al.
source = """
__global__ void histogram_partial(
DTYPE *input,
uint *partial_histo,
uint input_size
){
int local_size = blockDim.x;
int group_indx = blockIdx.x * HISTO_SIZE;
int gid = (blockIdx.x * blockDim.x + threadIdx.x);
int tid = threadIdx.x;
__shared__ uint tmp_histogram[HISTO_SIZE];
int j = HISTO_SIZE;
int indx = 0;
// clear the local buffer that will generate the partial histogram
do {
if (tid < j)
tmp_histogram[indx+tid] = 0;
j -= local_size;
indx += local_size;
} while (j > 0);
__syncthreads();
if (gid < input_size) {
atomicAdd(&tmp_histogram[input[gid]], 1);
}
__syncthreads();
// copy the partial histogram to appropriate location in
// histogram given by group_indx
if (local_size >= HISTO_SIZE){
if (tid < HISTO_SIZE)
partial_histo[group_indx + tid] = tmp_histogram[tid];
}else{
j = HISTO_SIZE;
indx = 0;
do {
if (tid < j)
partial_histo[group_indx + indx + tid] = tmp_histogram[indx + tid];
j -= local_size;
indx += local_size;
} while (j > 0);
}
}
__global__ void histogram_sum_partial_results(
uint *partial_histogram,
int num_groups,
uint *histogram
){
int gid = (blockIdx.x * blockDim.x + threadIdx.x);
int group_indx;
int n = num_groups;
__shared__ uint tmp_histogram[HISTO_SIZE];
tmp_histogram[gid] = partial_histogram[gid];
group_indx = HISTO_SIZE;
while (--n > 0) {
tmp_histogram[gid] += partial_histogram[group_indx + gid];
group_indx += HISTO_SIZE;
}
histogram[gid] = tmp_histogram[gid];
}
"""
source = source.replace("HISTO_SIZE", "%d" % ret.shape[0])
source = source.replace("DTYPE", interop_pycuda.type_np2cuda_str(x.dtype))
prg = SourceModule(source)
# Calculate sizes for the kernel execution
kernel = prg.get_function("histogram_partial")
local_size = kernel.get_attribute(pycuda.driver.function_attribute.MAX_THREADS_PER_BLOCK) # Max work-group size
num_groups = int(math.ceil(x.shape[0] / float(local_size)))
global_size = local_size * num_groups
# First we compute the partial histograms
partial_res_g = pycuda.driver.mem_alloc(num_groups * ret.nbytes)
kernel(x_buf, partial_res_g, np.uint32(x.shape[0]), block=(local_size, 1, 1), grid=(num_groups, 1))
# Then we sum the partial histograms into the final histogram
kernel = prg.get_function("histogram_sum_partial_results")
kernel(partial_res_g, np.uint32(num_groups), ret_buf, block=(1, 1, 1), grid=(ret.shape[0], 1))
return ret
Performance Comparison¶
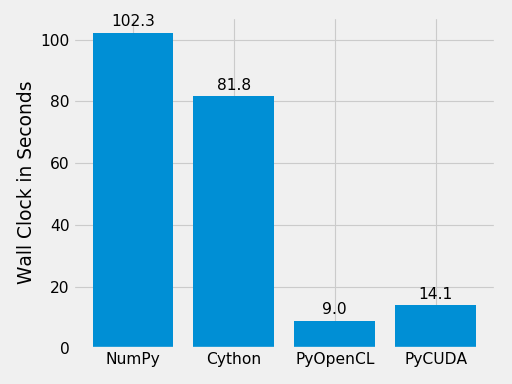
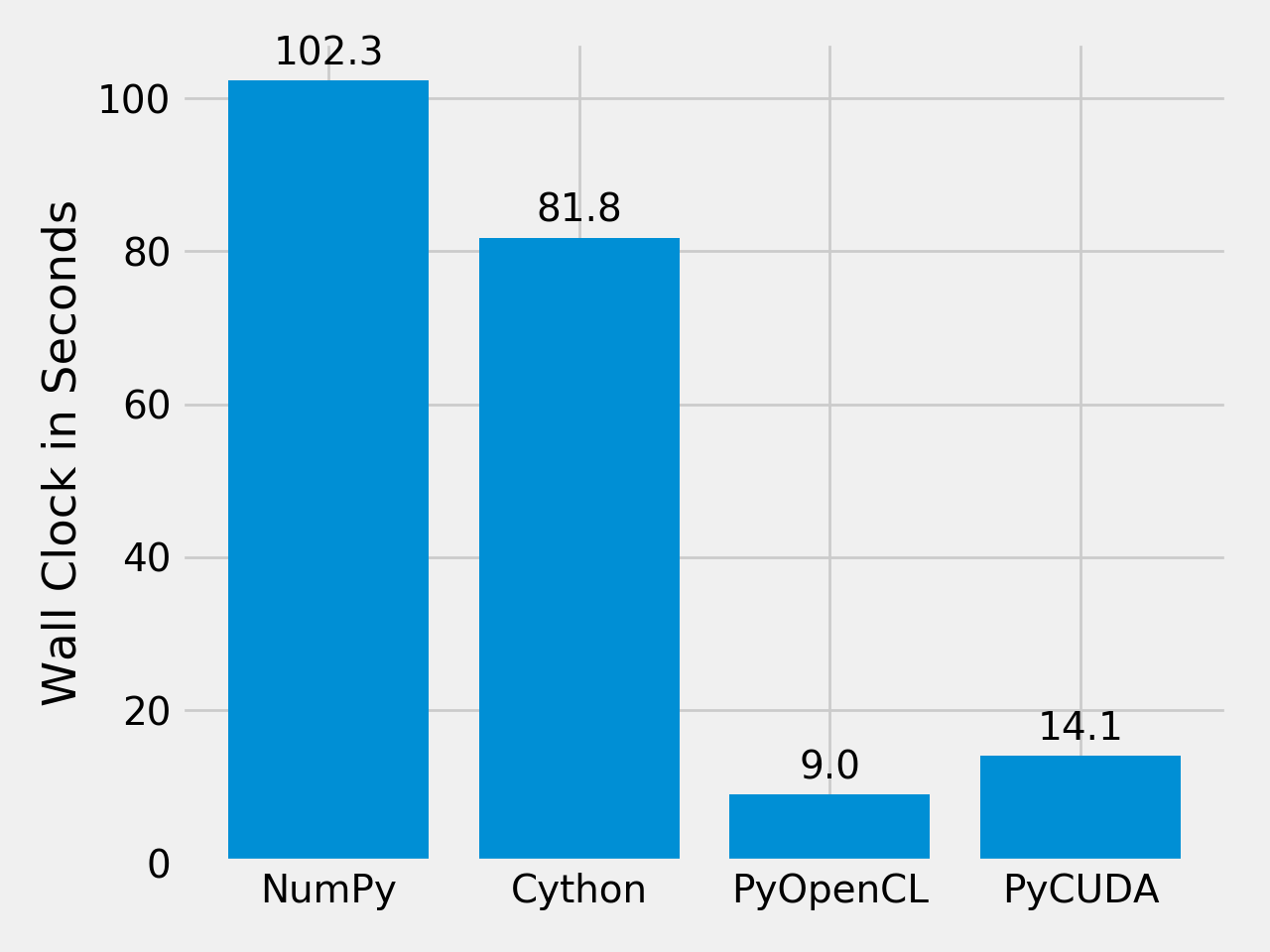
Finally, let’s compare the performance of the difference approaches. We run on a Intel(R) Core(TM) i5-6600K CPU @ 3.50GHz with 4 CPU-cores and a GeForce GTX Titan X (maxwell). The timing is wall-clock time including everything, in particular the host/device communication overhead.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
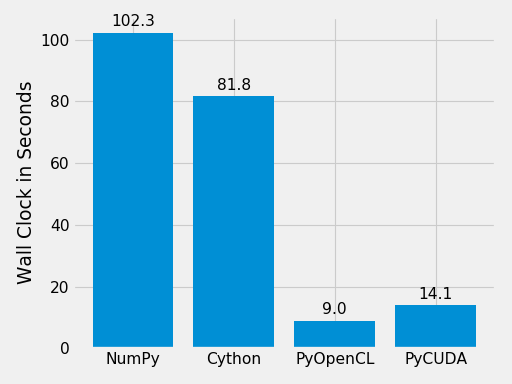
The timing code:
import numpy as np
import time
SIZE = 500000000
ITER = 100
t1 = time.time()
a = np.minimum(np.arange(SIZE, dtype=np.int64), 64)
for _ in range(ITER):
b = np.bincount(a)
t2 = time.time()
s = b.sum()
print ("Sum: %d, time: %f sec" % (s, t2 - t1))
Conclusion¶
Interoperability makes it possible to accelerate code that Bohrium doesn’t accelerate automatically. The Bohrium team constantly works on improving the performance and increase the number of NumPy operations automatically accelerated but in some cases we simply have to give the user full control.